(SOCAR) 신규 쏘카존 제안 프로젝트
들어가며
2022년 8월부터 2023년 2월까지 AIFFEL이라는 이름의 인공지능 교육과정에 참여했습니다. 이 포스트는 해당 과정의 최종 프로젝트에 대한 정리입니다.
카셰어링 업체 SOCAR로부터 45만여 건의 SOCAR 사용이력 데이터를 제공받았습니다.
이 데이터(이하 수요 데이터)를 바탕으로 하여, 자유롭게 주제를 정하고, 유의미한 결과를 내는 것이 이 최종 프로젝트(AIFFELTHON)의 과제였습니다.
다만, 주어진 데이터가 ‘수요’에 대한 데이터였던 만큼, 수요예측이라는 키워드에 맞출 필요는 있었습니다.
저희 팀은, 이 데이터를 바탕으로 하여 신규 쏘카존의 위치를 제안해보았습니다.
이 프로젝트에 대한 (원본 데이터를 제외한) 소스코드는 깃허브에 있습니다. 프로젝트의 상세한 진행경과는 노션에 기록되어 있습니다.
발표자료


발표자료의 목차입니다. 01과 02에서는 프로젝트의 전반적인 사항에 대해 대략적으로 이야기하고, 03부터 06까지는 네 단계에 걸쳐서 프로젝트의 진행상황을 적었습니다.

프로젝트의 배경 및 목적입니다.
저희 팀은 지역별로 쏘카의 이용 수에 차이가 있음을 먼저 관찰했습니다.
단순히 이용 수가 많고 적음을 넘어서서 이용 수가 증가세를 보이는지, 감소세를 보이는지 하는 것을 관찰할 수 있었습니다.
이러한 증감 경향을 지역별로 나누어 바라보는 것이 의미있을 것이라고 판단했습니다.
그중 수요가 증가할 것으로 예상되는 지역에 주목했습니다. 이 지역에 새로운 쏘카존을 만든다고 가정할 때, 신설될 쏘카존의 위치를 제안하는 것을 이 프로젝트의 목표로 삼았습니다.

전체적인 프로젝트의 구조입니다. 프로젝트의 전체 내용을 한마디로 요약하면 다음과 같습니다.
경기도 지역을 6개의 군집으로 나눈 후 각 군집별로 수요를 예측하여 미래에 수요가 증가할 것으로 예상되는 군집을 선정한 뒤, 해당 군집의 한 지역에 대하여 신규 쏘카존의 위치를 제안한다.
프로젝트의 전체 과정은 네 단계로 나누어보았는데, 각각 데이터 분석, 군집화, 수요예측, 신규존 제안 입니다. 각각의 단계에 대한 설명은 다음과 같습니다.
- 데이터 분석 : 군집화에서 사용할 feature들을 정한다.
- 군집화 : k-means clustering을 통해 경기도의 42개 지역을 6개의 군집으로 나눈다.
- 수요예측 : 각 군들에 대하여 가장 수요가 많이 증가할 것으로 예상되는 군집(지역)을 선정한다.
- 신규존 제안 : 선정한 지역에 대하여 신규 쏘카존의 위치를 제안한다.
이용 수와 '수요'는 같은 말입니다.
쏘카 서비스가 몇 회 이용되었는지를 나타내는 수치입니다.
feature를 나타낼 때에는 이용 수라는 단어를, 일반적인 의미로 쓸 때는 '수요'라는 단어를 사용하겠습니다.
이것은 문맥에 따라 지역별 수요가 될 수도 있고, 일자별 수요가 될 수도 있으며, 군집별 수요가 될 수도 있습니다.
1 데이터 분석
저희 팀은 경기도 지역을 타겟으로 삼았습니다.
그 이유는, 제공받은 수요 데이터는 대부분이(77.96%) 경기도의 데이터였기 때문이었는데요.
수요 데이터는 지역1(대지역) 기준으로 경기도, 울산광역시, 전라북도, 세종특별자치시, 부산광역시의 다섯 곳의 지역을 포함하고 있었습니다.
데이터의 양이 가장 많은 것 외에도 행정적인 유사성이나 지리적인 통일성을 고려했을 때에도, 경기도를 주요 관심지역으로 삼는 것이 가장 타당해보였습니다.

경기도 지역의 데이터는 지역2(소지역)을 기준으로 16개 소지역으로 나뉩니다.
그것들은 시, 군, 구를 의미합니다.
- 시(市) : 자치구를 따로 가지고 있지 않은 중소도시 (e.g. 구리시, 하남시)
- 군(郡) : 시보다 규모가 작은 지역 (e.g. 가평군, 연천군)
- 구(區) : 자치구를 가지고 있는 대도시의 자치구(e.g. 성남시 수정구, 안양시 만안구)
수요 데이터가 제공하는 시/군/구가 16개인 것과는 달리, 경기도의 시/군/구는 총 42개입니다.
그러니까 수요 데이터는 경기도의 모든 시/군/구의 데이터를 포함하고 있지 않습니다.
여기에서 전체 프로젝트의 내용을 관통하는 아이디어가 나왔습니다.
만약 42개 지역을 군집화하고, 16개 지역에 대한 수요들을 바탕으로 군집별 수요 증감을 예측한다면, 수요 정보가 없는 지역에 대해서도 수요의 증감을 간접적으로 예상할 수 있을 것이라고 생각했습니다.
이것이 가능하려면 군집화가 ‘잘’ 되어야 합니다. 카셰어링 수요를 잘 반영하는 군집화가 되어야 합니다. 다시 말해, 카셰어링 수요와 관련된 지역별 feature들을 잘 선정하고 그 feature들을 통해 군집화를 진행해야 합니다.
카셰어링 수요를 잘 반영하는 feature를 찾기 위해 먼저 논문들을 살폈습니다. 대표적으로 참고한 논문은 「서울시의 카셰어링 이용도에 대한 지역적 요인특성분석」입니다. 이 논문의 결론을 읽어보면 어떤 지역이 업무중심지역이거나 역세권, 혹은 대학가이면 카셰어링 수요가 많다고 되어 있습니다. 또한 해당 지역이 주거지인지 여부 또한 카셰어링 수요에 영향을 미친다는 언급이 있습니다. 그밖에 대중교통이 용이한 지역이어도 카셰어링 수요가 많다는 것과 토지용도 또한 고려의 대상이 될 수 있다는 말들도 있습니다.
이러한 사실들을 바탕으로 하여 총 17종의 feature들을 선정하고, 경기도의 42개 지역에 대하여 해당 feature들에 대한 데이터를 모았습니다.
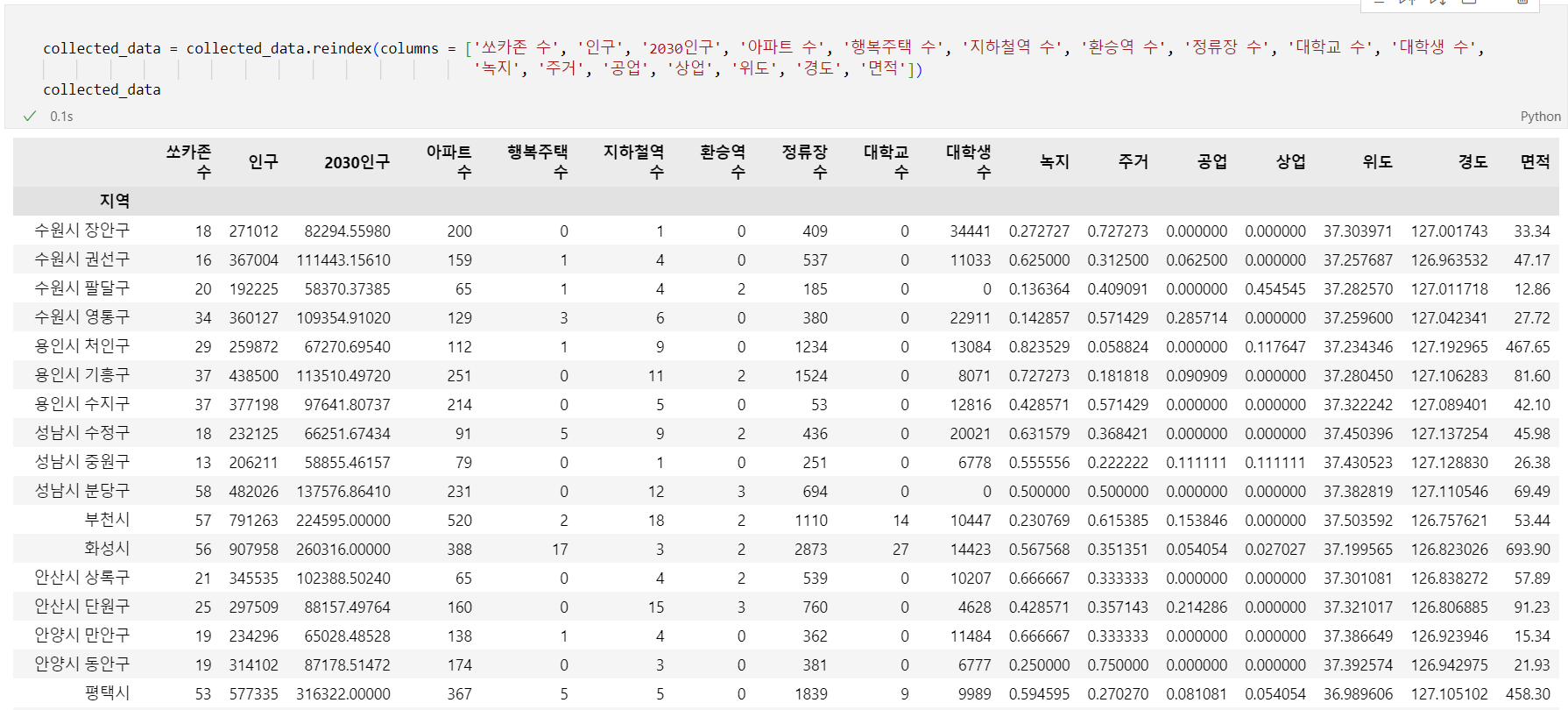
그리고 이 데이터를 지역별 데이터라고 명명했습니다.
수집한 데이터의 feature들은 쏘카존 수, 인구, 2030인구, 아파트 수, 행복주택 수, 지하철역 수, 환승역 수, 버스정류장 수, 대학교 수, 대학생 수, 녹지, 주거, 공업, 상업, 위도, 경도, 면적입니다.
분류해서 다시 적어보면
| 주거 | 인구 | 2030인구 | 아파트 수 | 행복주택 수 |
|---|---|---|---|---|
| 교통 | 쏘카존 수 | 지하철역 수 | 환승역 수 | 버스정류장 수 |
| 대학 | 대학교 수 | 대학생 수 | ||
| 토지용도 | 녹지 | 주거 | 공업 | 상업 |
| 지리 | 위도 | 경도 | 면적 |
와 같이 쓸 수 있습니다.
위 feature들에 대한 설명은 다음과 같습니다.
- 시/군/구별 인구에 해당하는
인구데이터는 쉽게 구할 수 있었으나,2030인구(20대, 30대 인구)는 직접 데이터를 얻을 수는 없었습니다. 하지만 각 광역(자치구를 가지고 있는 대도시)의 나이대별 인구비율 데이터를 찾게 되었고, 이를인구데이터와 결합하여2030인구를 간접적으로 구했습니다. - feature들 중 수작업을 통해 데이터를 확보한 것은 토지용도에 해당하는
녹지,주거,공업,상업입니다. 지도를 통해 살펴보며 해당 시/군/구의 하위행정구역(e.g. 동, 읍, 면)에 대하여녹지,주거,공업,상업중 하나의 토지용도를 결정했습니다. 해당 시/군/구의녹지데이터는 해당 시/군/구의 하위행정구역 중 얼마만큼의 비율의 하위행정구역이녹지인지를 나타냅니다. 예를 들어, 수원시 장안구의 경우 열 개의 동을 가지고 있고, 각각의 동들이
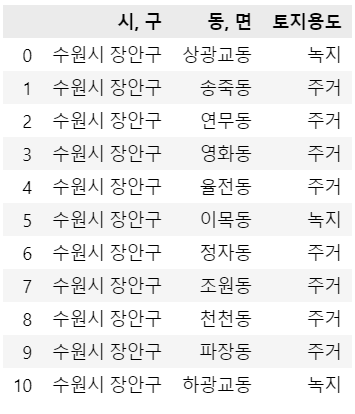
와 같은 토지용도를 가지고 있다면, 3개 동이 녹지이므로 수원시 장안구 지역의 녹지는 $\frac3{11}=0.2727$로 정합니다.
8개 동이 주거이므로 수원시 장안구 지역의 주거는 $\frac8{11}=0.7273$으로 정합니다.
그밖에 공업과 상업은 한번도 나타나지 않았으므로 각각 0입니다.
위도와경도,면적은 지리적인, 혹은 기하학적인 feature이므로 쏘카 수요와 직접적으로 연관이 있다고 말할 수 없습니다. 이것들은 참고용으로, 혹은 대조군의 역할을 위해 구해놓은 것입니다.
이 17종의 feature들 중 이용 수(쏘카 사용량)와 상관성이 높은 열 개의 feature를 선별했습니다.
여기에서 ‘상관성’이라 함은 상관계수(pearson correlation coefficient)를 의미합니다.
(상관계수에 관해서는 블로그에 그 개념을 정리해본 바가 있습니다.)
또, 이용 수는 지역별 쏘카 수요를 의미하는 것으로, 수요 데이터로부터 손쉽게 얻을 수 있습니다.
17종의 feature에 대한 이용 수와의 상관계수는 다음과 같습니다.
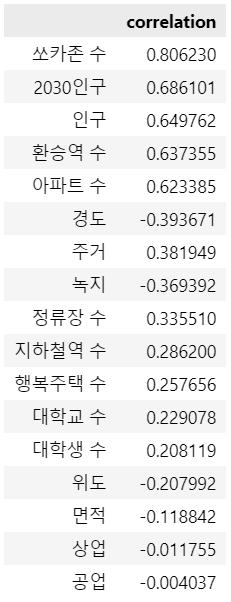
이것은 몇가지 점에서 예상과는 조금 다릅니다.
아까 논문에서는 대학가에서 쏘카의 수요가 높을 것으로 보았습니다.
하지만, 대학 수도, 대학생 수도 이용 수와의 연관성이 낮은 것으로 나옵니다.
이것은 아마도, 최소 지역단위를 시/군/구로 잡았기 때문인 것으로 보입니다.
만약 더 세분화하여, 동/읍/면을 기준으로 데이터를 수집했다면 대학 수와 대학생 수는 ‘정상적’으로 이용 수와의 연관성이 높게 나타났을 수 있었을 것입니다.
또 한가지는, 대학 수의 경우에 일반 4년제/2년제 대학은 물론, 소규모의 대학기관/대학원도 모두 포함시켜 얻은 데이터이기 때문에, 일반적으로 말하는 ‘대학가’의 개념과는 조금 다른 의미를 가지게 된 것인지도 모르겠습니다.
반대로, 경도는 예상과는 다르게 이용 수와의 연관성이 높은 것으로 나옵니다.
이것은 경기도의 지리적 특성상, 경기도의 서쪽이 서울과 가깝고, 동쪽으로 갈 수록 서울과 멀어지는 것을 반영한 것으로 보입니다.
그밖의 점들에 있어서는 예상 범위 안의 결과를 보여줍니다.
쏘카존 수는 당연히 이용 수와 높은 상관관계를 보입니다.
이것은, 쏘카존이 경기도 전역에 잘 분포되어있다는 것을 나타내기도 합니다.
쏘카 수요가 많은 곳에 쏘카존이 많이 포진되어있다는 뜻이기 때문입니다.
또한, 2030인구, 인구, 아파트 수와 같은 주거 특성의 feature들은 예상대로 이용 수와 상관성이 있음이 나타납니다.
그리고, 환승역 수, 정류장 수, 지하철역 수와 같은 교통 특성의 feature들도 대체로 높은 상관성을 띠고 있습니다.
토지용도의 경우에는 주거와 녹지가 이용 수와 각각 양의 상관관계와 음의 상관관계를 보입니다.
아래의 두 그래프는 각각 이용 수와의 상관관계가 높은 쏘카존 수와 상관관계가 낮은 대학교 수와의 scatter plot입니다.
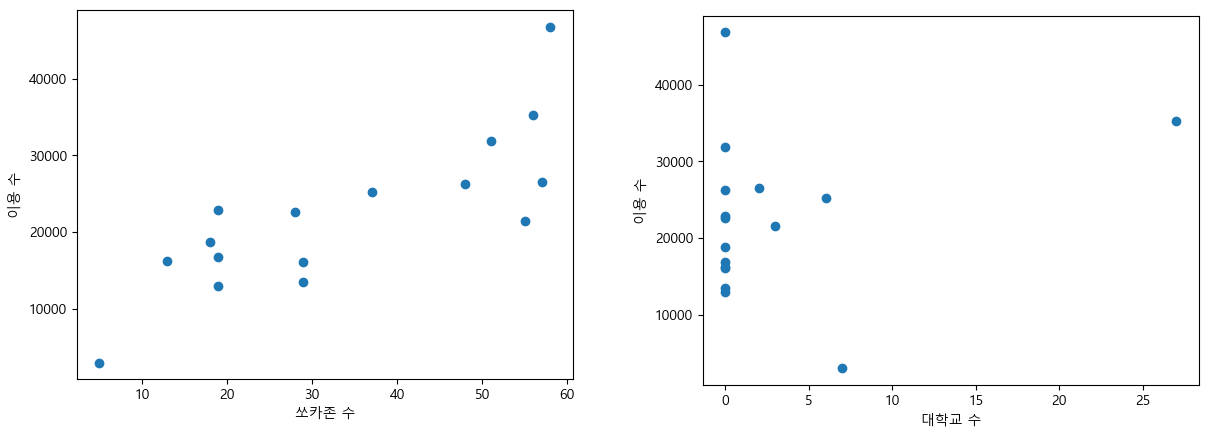
상관관계분석(Pearson correlation analysis)의 결과로 총 17개의 feature들 중 여섯 개의 feature를(위도, 경도, 면적, 대학교 수, 대학생 수, 행복주택 수) 제거하여 11개의 feature들만을 남기게 됩니다.
이 중, 대학교 수와 대학생 수는 상기의 이유로, 상관분석의 결과로 제외한 것이고, 위도, 경도는 참고삼아 구해놓은 것을 여기에서 뺐다고도 할 수 있습니다.
면적은 애초에 카셰어링과는 관련이 없는 feature이지만, 그럴 것을 예상하고 넣어본 대조군에 해당합니다.
즉, 의미적으로 혹은 상식적으로 이용 수와 상관성이 낮아보이는 ‘면적’이 정말로 correlation의 절댓값이 낮은지 확인해본 것입니다.
상관분석을 통해 선별한 11개의 feature들의 목록은 다음과 같습니다.
쏘카존 수인구2030인구아파트 수지하철역 수환승역 수버스정류장 수녹지주거공업상업
사실, 상관관계분석 말고도 선형회귀분석(linear regression analysis)도 해봤습니다. 하지만, 시간이 촉박하여 많은 결과를 도출해내지 못했고, 도출해냈다고 하더라도 그 결과를 신뢰하기 어려웠기 때문에 프로젝트의 전체흐름에 반영시키지 않았습니다.
2 군집화

위에서 도출한 11개의 feature에 대한 지역별 데이터를 통해 경기도의 42개 지역을 군집화했습니다.
여러 군집화 방법 중 가장 기본적인 군집화 알고리즘인 K-means clustering을 사용했습니다.
이번 프로젝트에 관한 K-means clustering은 다음과 같이 서술될 수 있습니다.
지역별 데이터는 11개 feature에 대한 42개 지역 정보입니다.
그것을 11차원의 유클리드 공간에 놓인 42개의 점들 $\boldsymbol x_1$, $\boldsymbol x_2$, $\cdots$, $\boldsymbol x_{42}$ 이라고 생각할 수 있습니다.
이 42개의 점들을 $K$개의 군집 $S_1$, $S_2$, $\cdots$, $S_K$으로 묶습니다 ;
이때 묶는 방식은, 군집들이 각 군집의 무게중심(centroid, $\mu_k$)에 잘 뭉쳐지는 방식으로 묶는 것입니다. 다시 말해,
\[\sum_{k=1}^K\sum_{\boldsymbol x\in S_k}||\boldsymbol x-\mu_k||^2\tag{$\ast$}\]이 최소화되도록 하는 군집 $S=\{S_1, S_2, \cdots, S_{K}\}$를 찾습니다. 이때, 최소화해야하는 위 식 $(\ast)$의 값을 distortion이라고도 부릅니다. distortion의 최솟값을 $D(K)$라고 쓰면,
\[D(K)=\min_{S}\sum_{k=1}^K\sum_{\boldsymbol x_i\in S_k}||\boldsymbol x_i-\mu_k||^2\]입니다. 이때, $K$의 값이 증가할 수록 $D(K)$의 값은 감소하는 것이 당연합니다. 한편, $D(K)$의 값이 작아지는 $K$값을 선정하는 것이 바람직하지만, 군집의 수($=K$)가 너무 많아지면 군집화하는 의미가 별로 없습니다. 따라서, $D(K)$의 값이 처음으로 최솟값과 비슷한 값에 도달하는 $K$의 값, 다시 말해, $D(K)$의 그래프가 평평해지는 순간의 $K$를 선정하는 것이 가장 좋습니다. 실제로, 저희 문제에서 $K$에 따른 $D(K)$의 그래프는
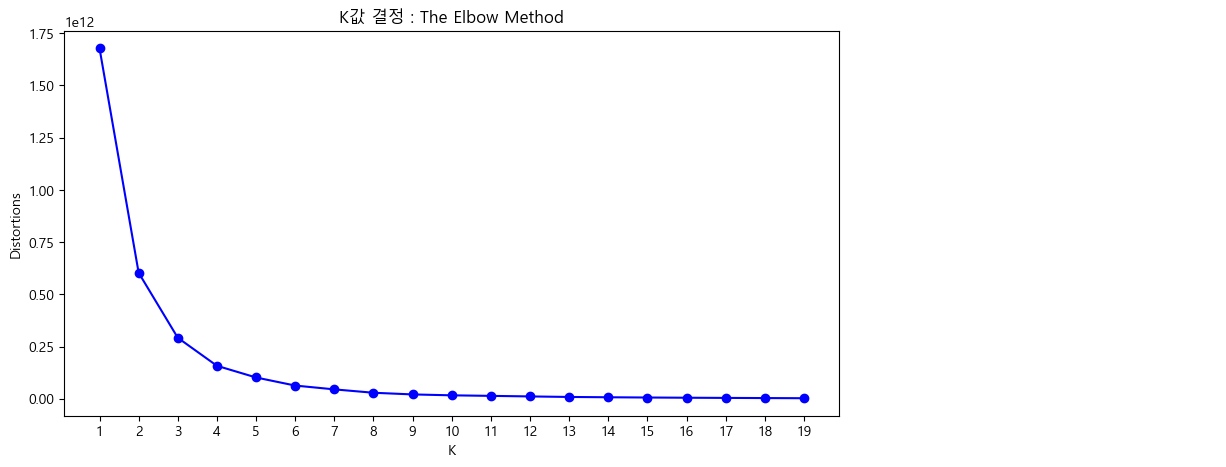
와 같이 나타납니다. 따라서, $K$값은 4,5,6,7,8 중의 하나의 값으로 선정하는 것이 적당해보입니다.
그러나, 언제나 그렇듯 군집의 수($K$)를 정하는 것은 애매한 일입니다. $K=5$로 정하나, $K=6$으로 정하나, 아니면 $K=8$으로 정하나, distortion의 관점에서는 아주 큰 차이가 있다고 말할 수 없습니다. 하지만 군집화의 목적을 다시 한 번 상기해볼 필요가 있습니다. 군집화를 하는 이유는, 다음 단계인 ‘수요예측’에서 ‘수요가 증가할 것으로 예측되는 군’을 판별하기 위함입니다.
따라서, 실제 프로젝트에서는, 각각의 $K\in\{4,5,6,7,8\}$값들에 대하여 수요를 예측했을 때, 수요의 군별 증감이 뚜렷이 나타나는 값으로 $K$를 정했습니다. 수요의 군별 증감이 가장 확연하게 나타나는 경우는 $K$가 6인 경우였기 때문에, $K=6$로 정했습니다. $K=6$으로 두어 경기도의 42개 시/군/구를 군집화한 결과는 아래와 같습니다.

프로젝트의 최종 목표는 신규 쏘카존의 위치를 제안하는 것이지만, 위의 그림 역시 이번 프로젝트에서 얻을 수 있었던 의미있는 중간 결과라고 할 수 있을 것입니다.
군집화에 관해서 자세한 분석을 시도해보기도 했지만, 성공적이지는 않았습니다. 그러니까, $K$값을 조금씩 변경하면서, 혹은 feature들의 조합을 조금씩 바꿔가면서 전체적인 군집화가 어떻게 변하는지를 살펴본다면, 각 군집의 의미나 형태에 대하여 조금 더 확실하고 엄밀한 결과를 얻어냈 수 있다고 생각했습니다. 하지만 제한된 데이터의 종류와 촉박한 시간의 한계로 이와 관련된 의미있는 결과를 도출해내지는 못했습니다.

다만 두 개의 군집 $A$와 $D$에 대해서, 각 feature들의 평균(정확하게는 min-max scale된 값)을 살펴보았습니다.
예를 들어, $A$군의 쏘카존 수가 0.7403인 것은, 42개 시/군/구의 쏘카존 수
을 minmax scaling하여
\[\text{minmax}(a_i)=\frac{\max a_i-a_i}{a_i-\min a_i}\]를 얻고 ($1\le i\le42$) 이것을 다시 $A$군에 대해서만 평균낸 것입니다 ;
\[\frac1{|S_1|}\sum_{\boldsymbol x_i\in S_1}\text{minmax}(a_i)=0.7403\]$A$ 군의 경우 지하철역 수, 환승역 수, 정류장 수와 같은 교통 특성의 feature들과 인구, 2030인구, 아파트 수와 같은 주거 특성의 feature들이 비교적 높은 값을 보이고 있습니다.
다시 말해, 용인시 기흥구, 성남시 분당구, 시흥시, 김포시, 고양시 덕양구, 파주시, 의정부시와 같이 교통과 주거 측면에서 발달된 도시들끼리 뭉쳐서 $A$군을 이루었습니다.
반면, $D$군은 반대입니다.
녹지의 값이 크게 나타났을 뿐 다른 값들은 적은 값으로 표시되고 있습니다.
실제 지도에서도, $D$군을 이루는 양평군, 여주시, 과천시, 포천시, 동두천시, 가평군, 연천군 등은 경기도에서 상대적으로 도시화가 덜 진행된 지역들입니다.
지리적으로도, 과천시와 동두천시를 제외하면 강원도와 맞닿아있는 지역들이 $D$군을 이루고 있다는 것을 확인할 수 있습니다.
이 군집화의 결과를 이번에는 PCA를 통해 시각화해보았습니다. 즉, 두 개의 principal component들을 가지고 평면 위에 42개 점들을 찍으면, 그것들은 각기 군에 따라 잘 뭉쳐있는 것을 확인할 수 있습니다.
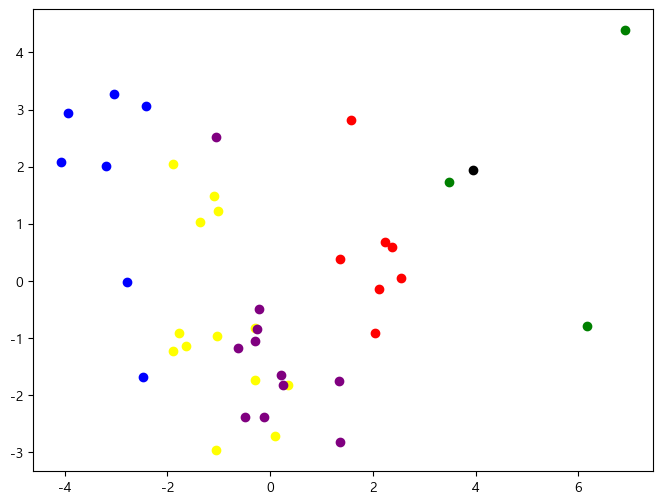
3 수요예측
이번에는 각각의 군들에 대하여 미래의 수요를 예측해봅니다.
여기에서 ‘미래’라고 하는 것의 의미는 다음과 같습니다.
주어진 수요 데이터의 시작시점은 2019년 1월 1일이고 종료시점은 2019년 11월 30일입니다.
그 중 8:2의 시점에 해당하는 2019년 9월 25일을 ‘현재’ 시점으로 잡고, 이 현재시점에 대한 미래 예측을 하는 것입니다.
조금 더 풀어서 설명하자면, 수요 데이터는 45만 건의 쏘카 사용내역에 관한 데이터였고, 우리는 그 중 일부(77.96%)인 35만 건의 경기도의 쏘카 사용내역을 가지고 있습니다.
이것을 여섯 개의 군으로 나눈 후 다시 일별로 잘라서 각 군별로 시간에 따른 수요 데이터를 얻을 수 있습니다.
이때, $F$군에 대해서는 시계열 데이터를 얻을 수 없습니다.
$F$군은 하나의 지역(평택시)으로 이루어져있는데, 수요 데이터에 평택시의 데이터는 포함되어 있지 않기 때문에 그렇습니다.
따라서, 총 5개의 시계열 데이터를 얻게 됩니다.
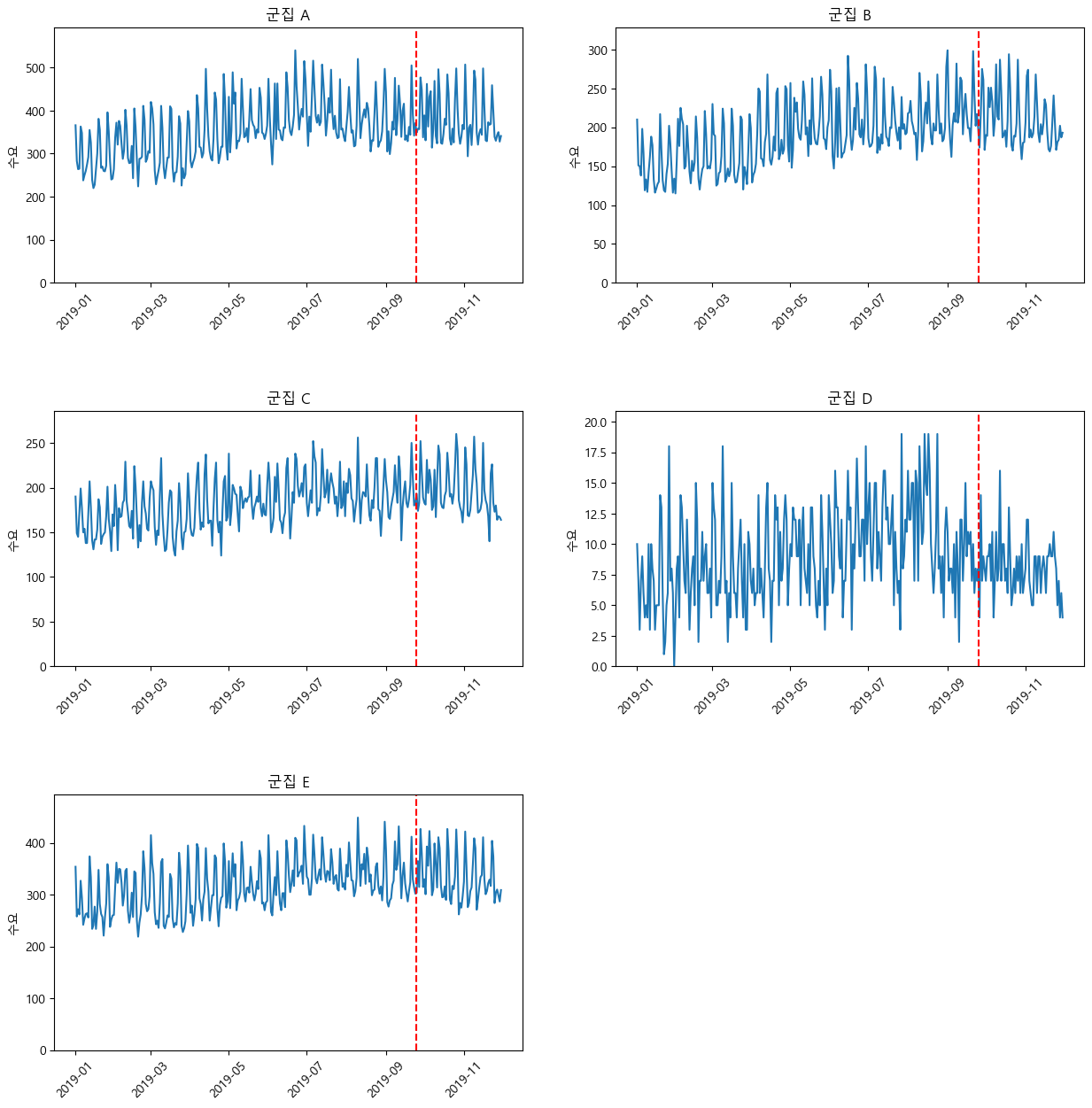
이 다섯 개의 시계열 데이터를, 아까 언급한 대로 2019년 9월 25일을 현재 시점으로 설정하여, 과거 데이터들을 통해 학습하여 미래 데이터를 예측합니다. 예측에 사용한 모델은 두 종류로, baseline에 해당하는 linear model과 main model에 해당하는 SARIMA입니다. linear model로 얻는 결과는 다음과 같습니다.
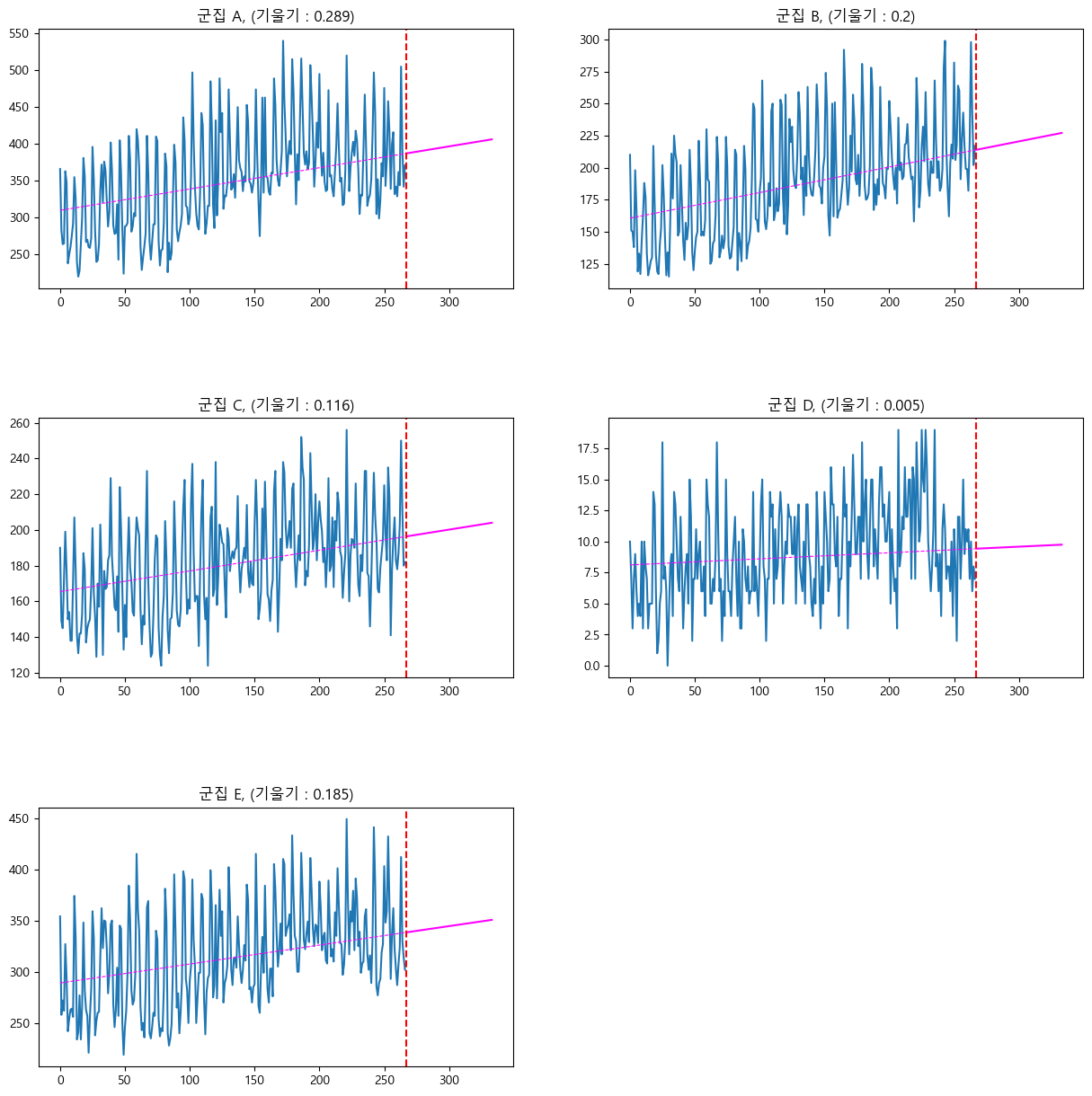
다시 말하지만, 이것은 과거(2019.1.1 ~ 2019. 9.24)의 데이터를 통해 학습하여 미래(2019. 9. 25 ~ 2019. 11. 30)의 수요를 예측하는 것입니다. 위의 그래프들에서 과거 데이터는 기존 그래프 그대로 표시하였고(파랑), 현재시점을 빨간 점선으로 표시했습니다. 또한, linear model로 예측한 데이터의 추세를 보라색 실선으로 표시했습니다.
사실 수요예측의 목적은 여섯 개의 군들 중 ‘미래에 수요가 증가할 것으로 예측되는’ 군을 찾는 것이기에 여기에서 끝내도 되긴 합니다. 즉, 각 linear model의 기울기 중에서 가장 가파른 것이 $A$이고 그 다음이 $B$이므로, $A$, $B$가 가장 적합한 후보라고 생각할 수 있습니다. 하지만, 조금 더 확실한 결과는 다음과 같이 표로 표시할 수 있습니다.
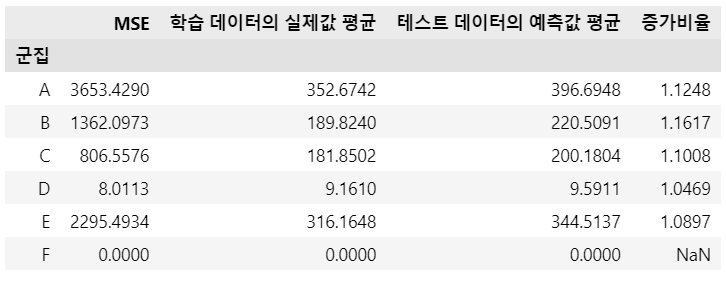
이것은, 과거 데이터(학습한 데이터)의 평균과 미래 데이터(예측한 데이터)의 평균 사이의 비율을 계산해본 것으로, 이 비율에 의하면 $B$, $A$ 순으로 수요의 가파른 증가가 예측되는 것이 보입니다. 이러한 접근법은 ‘얼마나 잘 예측했는가’를 말해주는 MSE 값도 계산할 수 있게 해줍니다. 모든 군에 대한 MSE의 산술평균은 $1354.2648$로 나타납니다.
하지만 조금 더 정확한 결과를 위해서, 그리고 다시 한 번 사실을 확인하기 위해서 baseline model인 linear model보다 복잡하고 정교한 모델인 SARIMA 모델을 적용해봅니다.
사실, 이 시계열은 7일의 주기를 가지는 시계열입니다.
쏘카 이용 수에 대한 그래프를 그리면 (전체 그래프이건, 군별 그래프이건, 개별적인 지역에 대한 그래프이건) 이용 수는 주말에 많고 주중에 적은 경향을 띱니다.
따라서 이러한 주기성을 가지는 시계열을 linear model로 예측하는 것은, 회귀에 관점에서 적절하지 않은 것일 수 있습니다.
이에, 주기성(Seasonality)을 잘 반영해주는 SARIMA 모델을 사용했습니다.
SARIMA 모델의 결과는 다음과 같습니다.
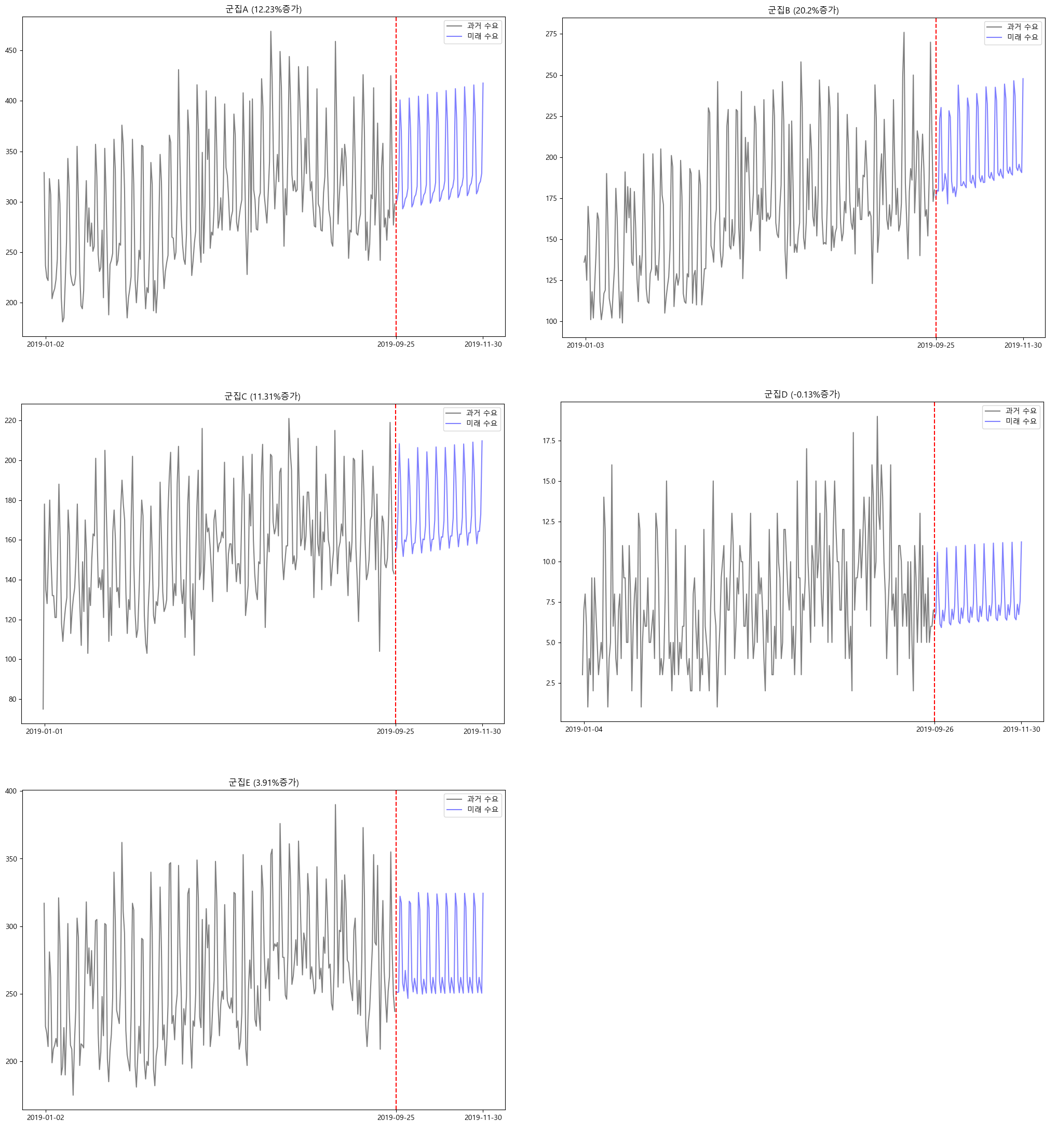

따라서, 여전히 $B$군과 $A$군에서 가장 가파른 수요 증가가 예측되며, MSE의 관점에서 SARIMA는 linear model에 비해 (예상대로) 높은 성능을 보입니다.
4 신규 쏘카존 위치 제안
프로젝트의 마지막 단계인 신규 쏘카존을 제안하는 단계입니다. 이전 단계인 수요예측 단계에서, 여섯 개의 군들 중 $B$군이, 미래에 수요가 증가할 것으로 예측되었습니다. $B$군은 다음과 같이 총 13개의 도시로 이루어진 군입니다.
- 구리시
- 군포시
- 성남시 수정구
- 성남시 중원구
- 수원시 장안구
- 수원시 팔달구
- 안성시
- 안양시 만안구
- 양주시
- 오산시
- 용인시 처인구
- 의왕시
- 이천시
그 중 네 개 지역인
- 구리시
- 성남시 수정구
- 성남시 중원구
- 안양시 만안구
에 대해서만 수요 데이터를 가지고 있었습니다.
그러니까 네 개 지역에 대해서만 수요의 증가가 확실하게 보장된 셈이지만, 저희 팀은 군집화가 올바르게 진행되었다는 가정 하에, 나머지 아홉 개 도시도 수요의 증가가 예측된다고 보고 있습니다.
여하튼, 이 중에서 하나의 지역, 수원시 팔달구를 지정하여 이곳의 신규 쏘카존 위치를 제안해보려고 합니다.
수원시 팔달구로 정한 이유는, 뒤이어 소개할 ‘적합도 점수’의 세 요소를 적절히 반영할 수 있는 지역이라고 생각했기 때문입니다. 또 한가지 이유는, 팔달구에 유독 공영주차장이 많았습니다(35곳). 새롭게 쏘카존을 만들 때에는 보통 공영주차장을 사용하게 되는데, 공영주차장이 충분히 있는 지역이어야 수많은 쏘카존 후보지들 중 괜찮은 후보지를 찾는 것이 의미를 가지게 됩니다.
신규 쏘카존의 위치를 제안하는 데 있어서 가장 주안점을 두었던 것은, 이 제안이 정성적인 제안이 아니라 정량적인 제안이었으면 좋겠다는 것이었습니다. 특정한 제안을 하는 데에 있어서 합당한 근거를 댈 수 있기를 바랐습니다. 그래서 선택한 것이, 적합도 점수를 도입한 것이었습니다.

아까, 수원시 팔달구에 35개의 공영주차장이 있다고 했었습니다. 각각의 공영주차장이 얼마나 신규쏘카존으로 적합한지를 점수로서 매길 수 있다면, 그것은 의미있는 나름대로 정량적인 제안이 될 것이라고 생각했습니다. 다만, 적합도 점수 식을 결정하는 데에는 세 가지 정도의 정성적인 가정을 할 수밖에 없었습니다.
첫번째 가정은 다음과 같습니다. 어떤 공영주차장 $P$에 대하여,
- 가정1 : $P$의 근처에 쏘카존들이 없을수록 $P$는 신규쏘카존으로 적절합니다.
즉, 기존 쏘카존들이 없는 곳에 새로운 쏘카존을 만드는 것이 바람직합니다. 지금 하려는 것이 새 쏘카존을 만드는 것이지, 기존 쏘카존에 차량을 증설하려는 것이 아니니까, 이 가정은 합당합니다. $P$ 위치에서 100m 떨어진 거리에 쏘카존 $S$가 있다면, 굳이 $P$에 쏘카존을 설치할 필요가 없을 것입니다. $P$ 위치에서 쏘카존을 사용하려던 사람은, 그냥 100m정도의 짧은 거리를 걸어서 쏘카존인 $P$에서 서비스를 사용하면 됩니다. 그런데 만약, $P$ 위치에 200m 떨어진 거리에 또다른 쏘카존 $S’$가 존재한다고 해도, 상황은 완전히 똑같습니다. 이용자는 여전히 100m를 걸으면 됩니다. 다시 말해, ‘$P$의 근처에 쏘카존이 없을수록’이라는 표현은, ‘가장 가까이 있는 쏘카존까지의 거리가 멀수록’이라는 말로 바꿔도 됩니다. 즉, 공영주차장 $P$에 대하여
- 가정1$’$ : $P$에서 가장 가까이 있는 쏘카존까지의 거리가 멀수록 $P$는 신규쏘카존으로 적절합니다.
따라서, $\text{score}_1(P)$을
\[\text{score}_1(P)=\text{$P$에서 가장 가까이 있는 쏘카존까지의 거리}\tag1\]로 설정하면, $\text{score}_1(P)$은 적합도 함수로서의 역할을 할 수 있습니다.
두번째 가정은 다음과 같습니다.
- 가정2 : $P$에서 가장 가까이 있는 지하철역까지의 거리가 멀수록 $P$는 신규쏘카존으로 적절합니다.
는 것입니다. 이것은 팀원 중 한 분의 의견을 반영한 것입니다. 그 분의 의견에 따르면, 지하철역까지의 거리가 가까우면, 사람들은 지하철을 타지 쏘카 서비스를 사용하지는 않는다는 것입니다.
앞서 언급했던 논문에서는,
둘째, 중장거리 노선의 버스 등 대중교통과의 연계를 위한 인프라조건이 양호한 지역을 근거지로 하는 카셰어링거점에 있어서 그 활용도가 두드러지는 것을 확인할 수 있었다.
와 같은 문장이 있었습니다. 해당 논문에서는 ‘지하철’이라는 직접적인 표현은 언급하지 않고 있지만, 아마도 지하철역 근처에서는 쏘카의 수요가 높을 것임을 예상할 수 있습니다.
어떤 점에서는, 기본적으로 수도권 대부분의 지하철역에 쏘카존이 형성되어있다는 사실을 통해 보면, 더이상 지하철역 근처에는 쏘카존을 만들 필요가 없다고 생각해볼 수 있습니다. 따라서, 신설하는 쏘카존의 이용대상은 역세권으로부터 멀리 떨어진 지역의 거주민이 될텐데, 그러한 이용자의 경우에는 지하철역과 멀리 떨어져있어야, 조금 더 카셰어링 서비스를 원한다라고 판단할 수 있습니다. 이것은, 실제 수원시 팔달구의 지도를 보면 더 명확하게 보입니다.
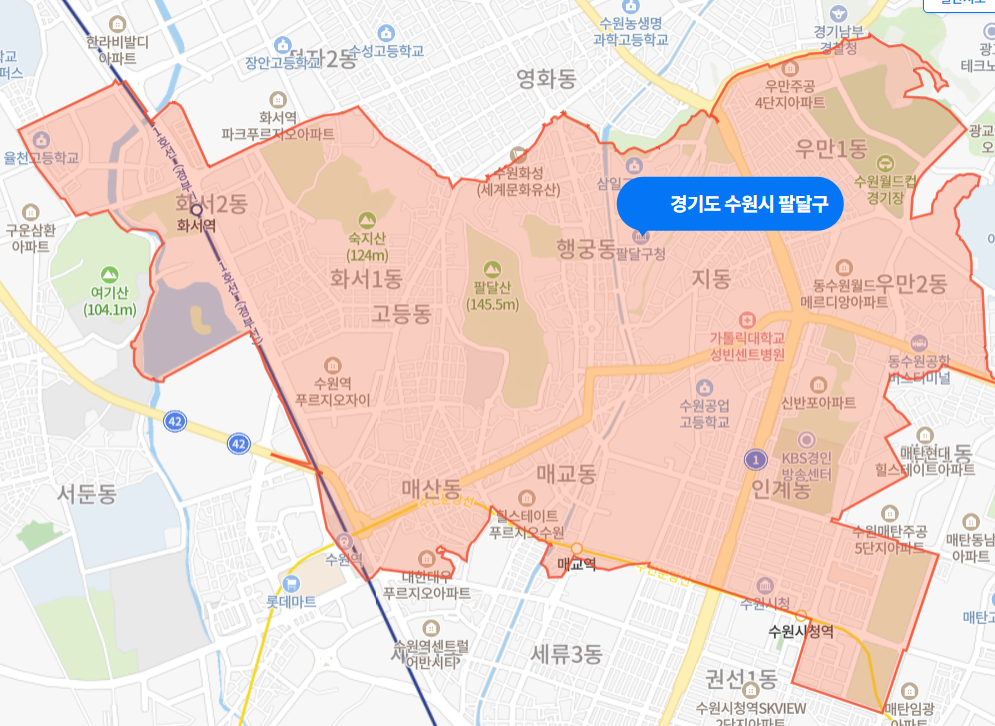
팔달구에는 수원역과 화서역, 매교역과 수원시청역의 네 개 역이 존재하고, 이 지하철역들을 중심으로는 다수의 쏘카존이 이미 형성되어 있습니다.
여하튼 그래서, 논란의 여지는 있지만, $\text{score}_2(P)$을
\[\text{score}_2(P)=\text{$P$에서 가장 가까이 있는 지하철 역까지의 거리}\tag2\]로 설정했습니다.
세번째 가정은 꽤 타당한 가정입니다.
- 가정2 : $P$의 근처에 아파트가 많을 수록(사람이 많이 살 수록) $p$는 신규쏘카존으로 적절합니다.
당연한 가정이라고 생각됩니다.
앞서, 쏘카 수요가 아파트 수, 인구, 2030인구와 같은 주거 특성의 feature와 양의 상관관계를 띤다고 했던 것이 반영된 셈이기도 합니다.
그리고 이번에는 앞선 두 가정에서처럼 ‘가장 가까운 아파트까지의 거리’를 가지고 식을 만들기에는 조금 아쉬운 감이 있습니다.
그보다는, $P$ 근처에 있는 여러 아파트들을 고려하는 것이 바람직하고, 각 아파트별로 세대수가 다른 것도 반영하는 것이 좋아보입니다.
따라서 $\text{score}_3$을
로 두어보았습니다. 즉, $P$를 중심으로 반경 3km의 세대수를 세는데, 2km 이내 세대와 3km 이내 세대는 조금 더 높은 가중치를 두어 세는 것입니다. $\frac 1i$와 같이 단순히 $i$의 역수로 가중치를 두기에는, 그 차이가 너무 심하게 날 것 같아서, 로그함수의 역수로 가중치를 두었습니다. 이것은 추천시스템에서 종종 사용되는 DCG(discounted cumulative gain)에서 그 아이디어를 따온 것입니다.
세 개의 식 (1), (2), (3)을 합쳐서
\[\text{score}(P)=\text{score}_1(P)+\text{score}_2(P)+\text{score}_3(P)\]으로 만들면, $\text{score}$는 적합도 점수를 나타내는 함수의 역할을 할 수 있습니다. 하지만 이대로는 큰 의미를 가지기 힘듭니다. 첫째로는 (1), (2)의 거리와, (3)의 세대수는 단위가 서로 다릅니다. 따라서 이것을 표준화(normalize)해줄 필요가 있습니다. 둘째로는, (1)과 (3)은 적합도 점수로서의 역할을 분명히 수행한다고 할 수 있지만, (2)는 논란의 여지가 있다고 했습니다. 이에, 세 값에 (3:1:3 정도로) 가중치를 두어 그 중요도를 지정해주면 좋을 것입니다. 셋째로, 기왕 점수로 나오는 것이니 0과 100 사이의 값으로 나오게 하면 보기가 더 편할 것입니다.
이 중 첫째와 둘째 사항은 다음과 같이 $\text{score}$ 식을 변형해
\[\text{score'}(P)=a_1\frac{\text{score}_1(P)-\mu_1}{\sigma_1}+a_2\frac{\text{score}_2(P)-\mu_2}{\sigma_2}+a_3\frac{\text{score}_3(P)-\mu_3}{\sigma_3}\]을 만들면 해결됩니다. 이때, $\mu_i$와 $\sigma_i$는 각각 35개의 공영주차장에 대한 $\text{score}_i(P)$값의 평균과 표준편차입니다. 셋째사항은 앞의 두 사항에 비하면 조금 복잡하지만, 그래도 가능합니다. 새로운 확률변수 $Z_i$를
\[Z_i=\frac{\text{score}_i(P)-\mu_i}{\sigma_i}\]로 두면($i=1,2,3$) $Z_i$들은 평균이 0이고 표준편차가 1인 분포를 따릅니다. 더 나아가, $Z_i$가 표준정규분포 $N(0,1)$을 따른다고 가정합니다. $35$가 충분히 큰 숫자이므로, 이와 같은 가정은 받아들일만 합니다. 마지막으로, $X_i$들이 각각 서로 독립(pairwisely independent)이라고 가정합니다. 그러면 $Z_i$들도 서로 독립입니다.
세 양수 $a$, $b$, $c$에 대하여 (나중에 $a=3$, $b=1$, $c=3$으로 둘 것입니다. 각각 가중치의 역할입니다.) 새로운 확률변수 $Y$를
\[Y=25\left(\sqrt{\frac{a}{a+b+c}}Z_1+\sqrt{\frac{b}{a+b+c}}Z_2+\sqrt{\frac{c}{a+b+c}}Z_3\right)+50\]로 잡으면
\[\begin{align*} E[Y] &=E\left[25\left(\sqrt{\frac{a}{a+b+c}}Z_1+\sqrt{\frac{b}{a+b+c}}Z_2+\sqrt{\frac{c}{a+b+c}}Z_3\right)+50\right]\\[10pt] &=25\sqrt{\frac{a}{a+b+c}}E[Z_1]+25\sqrt{\frac{a}{a+b+c}}E[Z_2]+25\sqrt{\frac{a}{a+b+c}}E[Z_3]+50\\[10pt] &=0+0+0+50\\[10pt] &=50\\ V[Y] &=V\left[25\left(\sqrt{\frac{a}{a+b+c}}Z_1+\sqrt{\frac{b}{a+b+c}}Z_2+\sqrt{\frac{c}{a+b+c}}Z_3\right)+50\right]\\[10pt] &=25^2\frac{a}{a+b+c}V[Z_1]+25^2\frac{a}{a+b+c}V[Z_1]+25^2\frac{a}{a+b+c}V[Z_1]\\[10pt] &=25^2 \end{align*}\]이며, 특히 $Y\sim N(50,25)$입니다. 그러면
\[P(0\le Y\le 100)=0.9545\]가 됩니다. 다시 말해 적합도 점수 $\text{SCORE}(P)$를 ($a=3$, $b=1$, $c=3$)
\[\text{SCORE}(P) =\frac{\sqrt3}{\sqrt7}\times\frac{\text{score}_1(P)-\mu_1}{\sigma_1} +\frac1{\sqrt7}\times\frac{\text{score}_2(P)-\mu_2}{\sigma_2} +\frac{\sqrt3}{\sqrt7}\times\frac{\text{score}_3(P)-\mu_3}{\sigma_3}\]로 잡으면, $\text{SCORE}(P)$는 95.45%의 확률로 0과 100 사이의 값을 가지게 됩니다. 사실 이것은 개별적인 공영주차장 $P$ 하나에 대하여 그 점수가 0과 100으로 나올 확률입니다. 따라서 35개의 공영주차장 $P_i$들이 모두 점수가 0과 100 사이로 나올 확률은 이보다 훨씬 줄어들어야 하겠지만, 실제로 수원시 팔달구에 대한 35개 공영주차장의 적합도 점수는 모두 0과 100 안으로 들어가게 됩니다.
이것들을 적용하면, 다음과 같은 결과가 나옵니다.
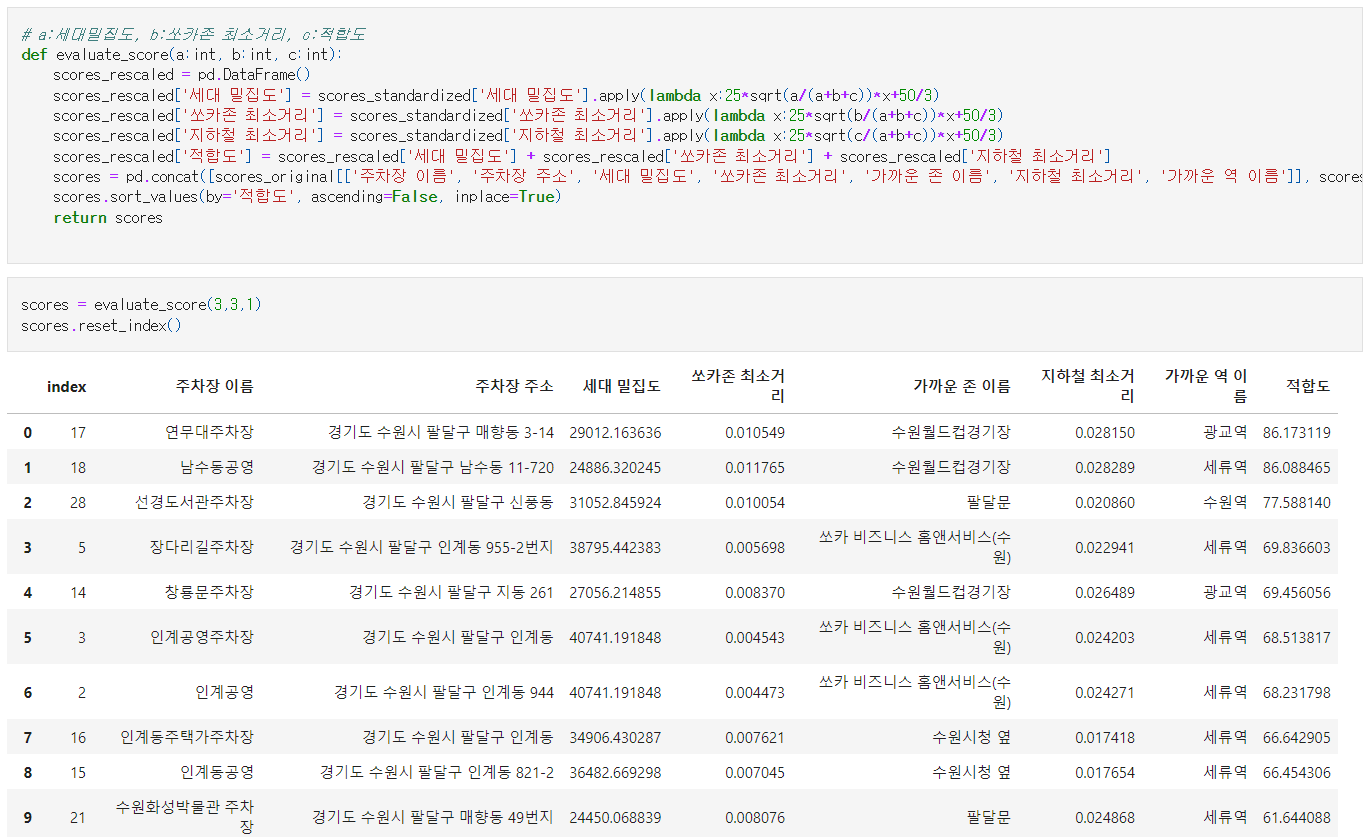
위 표에서 쏘카존 최소거리가 $\text{score}_1(P)$를, 지하철 최소거리가 $\text{score}_2(P)$를, 세대 밀집도가 $\text{score}_3(P)$를, 마지막으로 적합도가 $\text{SCORE}(P)$를 나타냅니다.
중요한 정보들만 모아서 간단히 쓰면
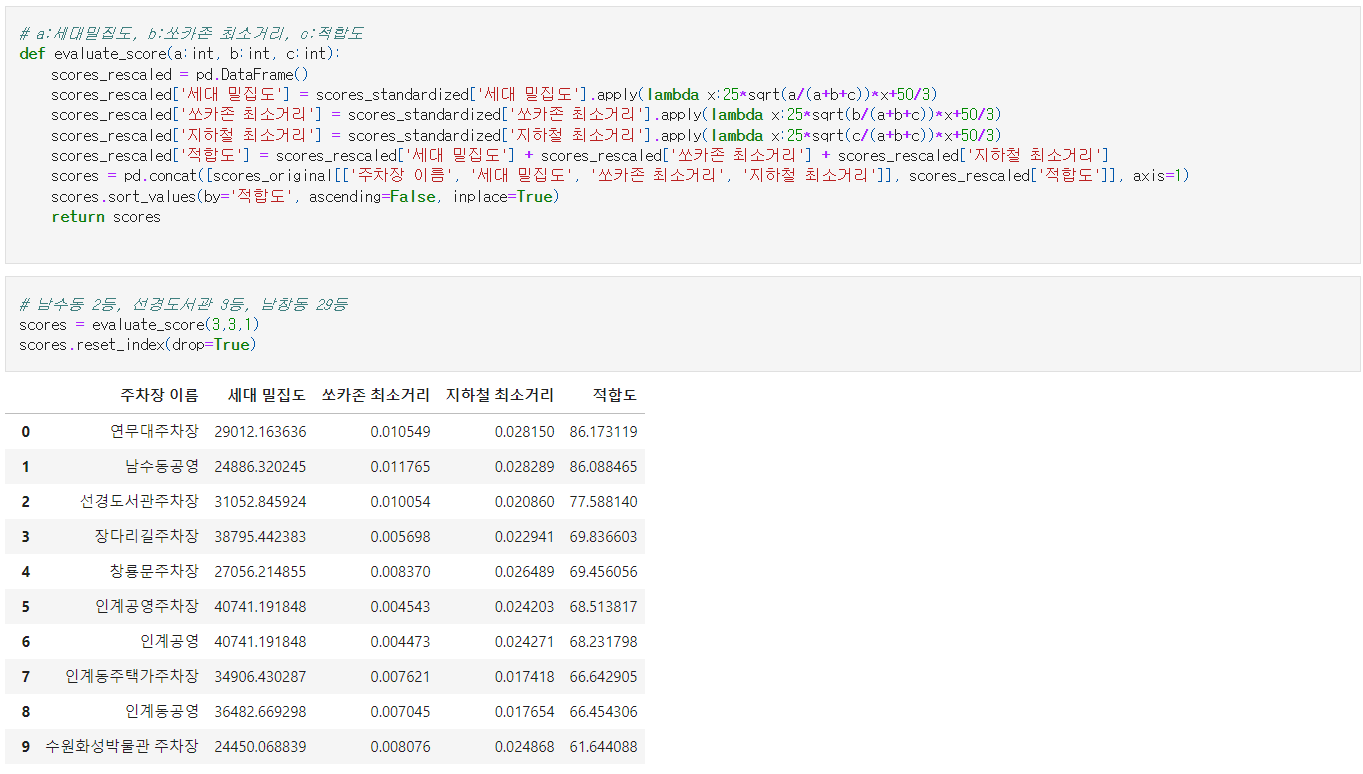
와 같이 됩니다. 따라서, 수원시 팔달구의 35개 공영주차장들 중 ‘연무대주차장’, ‘남수동공영주차장’, ‘선경도서관 주차장’이 가장 신규 쏘카존으로 적합한 지역임을 확인할 수 있습니다.

최종적으로 선택된 세 곳의 공영주차장이, 정말로 위의 세 가정을 만족시키는지는 다음과 같이 지도를 통해 확인해볼 수 있습니다.

위의 그림에서 1위인 연무대 주차장과 3위인 선경도서관 주차장을 지도 위에 표시하고(큰 P), 근처의 공영주차장(작은 P) 및 쏘카존(S), 그리고 주거단지를 대략적으로 표시해봤습니다. (지도상에는 모든 쏘카존이 다 표시되지 않았습니다. 실제로 수원역 부근과 화서역 부근의 쏘카존 몇 개가 누락된 그림입니다.)
그 결과, 연무대 주차장과 선경도서관 주차장은 다른 공영주차장들에 비해 정말로 주변 쏘카존으로부터 멀리 떨어져있고, 지하철역으로부터도 멀리 떨어져있으며, 근처에 주거단지가 형성되어 있음을 확인할 수 있습니다.
마치며
지금까지, 신규 쏘카존 제안과 관련된 프로젝트에 대하여 적어보았습니다. 적어놓고보니 잘한 부분도 있었지만, 어설프거나 허술한 부분들이 많이 눈에 띕니다. 미흡하거나 아쉽다고 생각될 수 있는 부분을 적어보면 다음과 같습니다.
첫째로, 신규 쏘카존 장소 추천이 목적이었다면 굳이 군집화가 필요했는가, 하는 부분입니다. 물론, 단순히 쏘카존 신설 위치를 제안하는 것만이 목적이었다면, 굳이 앞의 과정(군집화 및 수요예측)은 필요없을 수 있겠고, 어쩌면 별개의 프로세스처럼 보이기도 합니다. 하지만, 만약 쏘카존을 하나 신설하는 것이 꽤 많은 비용이 든다고 한다면, 그래서 신중하게 신설 쏘카존의 위치를 결정해야 한다면, 지금과 같은 방법이 효과적일 수 있을 것 같습니다. 관심지역 전지역에 대한 수요 정보가 주어져있지 않다는 가정 하에 (이런 사례는 빈번히 발생할 수도 있을 듯합니다.) 수요가 증가할 것으로 예측되는 특정한 지역을 선정하는 과정이 필요할 것이고, 그 과정에서 군집화가 사용될 수 있었을 것이라고 생각됩니다.
둘째로, 데이터의 부족 문제입니다.
앞서, 시/군/구 보다 더 세부적인 단위의 행정구역(예를 들면 동/읍/면)에 대한 데이터가 확보될 수 있었다면, 좀 더 정밀한 결과가 나왔을 수도 있었다고 언급했었습니다.
이것은 데이터를 확보할 수 없었기에 생긴 문제였습니다.
연령별 인구를 시/군/구 단위로 얻어내는 것 또한 간신히 할 수 있었고, 그나마도 시/군/구 단위에 대하여 아주 많은 feature들을 확보한 것은 아니라고 생각됩니다.
하지만, 시/군/구 단위의 여러 feature들을 얻어냈다고 하더라도, 수요 데이터 자체가 시/군/구 단위로 되어있었기에, 애초에 더 세분화된 분석을 할 수는 없었습니다.
데이터의 질 또한 문제일 수 있습니다.
앞서 대학의 수 데이터가 정확하지 않을 수 있음을 환기했었습니다.
그밖에도, 토지용도나 버스정류장 수에 대해서도 조금 더 체계적이고 일관된 데이터 확보 방법이 있었다면 더 의미있는 결과가 나왔으리라고 생각해봅니다.
셋째로, feature의 선별 문제입니다. 군집화에 사용된 feature들을 결정하기 위해 상관관계분석을 사용했고, 이것은 충분히 괜찮은 과정이었다고 생각됩니다. 하지만, 선형회귀분석을 적용해보지 못한 것은 아쉬움으로 남습니다. 상관분석으로는 서로 다른 두 변수에 대한 선형적인 상관성을 계산할 수 있습니다. 한편, 회귀분석을 사용하면 여러 변수가 한 변수에 어떻게 영향을 미치는지를 판단할 수 있다고 알고 있습니다. 군집화에 사용된 feature들 중 서로 관계되어 있는 경우가 있었는데, 그것들이 어떻게 군집화에 영향을 미쳤을지 하는 것을 고민해볼 만할 것 같습니다.
넷째로, 가정2입니다. (지하철역으로부터 멀리 떨어져있으면 신규쏘카존으로 적절하다. $\text{score}_2$) 최종적인 $\text{SCORE}$ 식을 결정하는 과정에서 $\text{score}_2$에 대한 가중치를 적게 주어 penalize하기는 했지만, 전체적으로 봤을 때, $\text{score}_2$는 선정 근거는 매우 빈약해보입니다. 조금 더 근거에 기반한 방식으로 $\text{score}_2$를 결정했으면 좋았을 것 같습니다.
다섯째로, $\text{SCORE}$ 식의 적절성이 실험적으로 검증되지 않았다는 것입니다. $\text{SCORE}$ 식은 단순히 이론적으로 postulate되기만 했고, 그 결과만 도출할 수 있었을 뿐, 정말로 $\text{SCORE}$ 식이 적절한 식인지는 확인되지 않았습니다. 예를 들어, SARIMA 모델이 (적어도 linear 모델보다는) 적절하다는 것이 MSE를 통해 검증될 수 있었습니다. 이러한, 데이터에 기반한 확인과정이 $\text{SCORE}$ 식에는 없었습니다.
이를 해결하기 위한 방법은 두 가지 정도로 생각됩니다. (a) 실제로 $\text{SCORE}$가 높은 공영주차장에 쏘카존을 설치하고, 그 수요를 추적하는 것입니다. 만약, $\text{SCORE}$ 식에 기반해 설치한 쏘카존이 예상대로 수요가 충분할 정도로 많으면, $\text{SCORE}$ 식을 믿어도 될 것입니다. 하지만, 이것은 시간적인 자원과 비용이 든다는 문제가 있을 수 있습니다. (b) 아니면, 문제를 완전히 바꿔서, 이미 존재하는 쏘카존에 대하여 이 $\text{SCORE}$ 식을 적용해볼 수 있습니다. 이를 통해, 현재 운영중인 쏘카존들이 정말로 필요한 위치에 있는지를 판단하는 척도로서 활용해볼 수 있을 것입니다.
댓글남기기