(Sutton, 4.4, 4.6절) Value Iteration, GPI
DP(dynamic programming)의 마지막 글이다.
policy iteration에 대한 글을 계속 이어나가다보니 양이 또 많아졌다. 심지어 코드도 추가했더니 글을 나누는 게 맞다는 판단이 생겼다.
4.4 Value Iteration
policy iteration은 정책평가와 정책개선의 반복이었지만, 정책개선도 그 자체로 반복 알고리즘이었다. 정책개선 한 번당 정책평가가 수렴할 때까지 기다리기에는 조금 지루할 수 있다. 그러니, 정책개선 한 번당 정책평가의 과정(sweep)을 한 번씩 수행하면 이 때에도 최적정책에 수렴하는 것이 알려져 있으며 이 과정을 value iteration이라고 한다고 Sutton은 쓰고 있다. 하지만 이건 비유적인 표현이라고 봐야 할 것 같다. 실제로 sweep과 PI를 반복적으로 적용하면 아래 식이 나오지는 않는다.
value iteration이란 가치함수를 다음과 같은 점화식으로 업데이트해나가는 방식을 말한다.
\[\begin{align*} v_{k+1}(s) &=\max_a\mathbb E\left[R_{t+1}+\gamma v_k(S_{t+1})\vert S_t=s, A_t=a\right]\\ &=\max_a\sum_{s',r}p(s',r|s,a)\left[r+\gamma v_k(s')\right]\tag{4.10} \end{align*}\]위의 식과 아래 식이 같다는 것은 다음 식에서 명백하다.
\[\begin{align*} &\mathbb E\left[R_{t+1}+\gamma v_k(S_{t+1})\vert S_t=s, A_t=a\right]\\ =&\sum_{s',r}p(s',r\vert s,a)\mathbb E\left[R_{t+1}+\gamma v_k(S_{t+1})\vert S_t=s,A_t=a,R_{t+1}=r,S_{t+1}=s'\right]\\ =&\sum_{s',r}p(s',r\vert s,a)\left[r+\gamma v_k(s')\right] \end{align*}\]value iteration은 policy iteration과는 많이 다르게 정책평가와 정책개선을 동시에 수행하는 셈이고 그런 점에서 나중에 나오는 Q-learning과 비슷하다.
value iteration을 통해 optimal value function $v_\ast$를 얻을 수 있다는 것을 증명하기 위해서 operator $\bar{\mathcal T}$를 다음과 같이 정의하자. Dawei Li, Zikun Ye의 자료를 참고하였다. 모든 $v:\mathcal S\to\mathbb R$에 대하여 $\bar{\mathcal T}v:\mathcal S\to\mathbb R$을
\[\begin{align*} \bar{\mathcal T}v(s) &=\max_a\sum_{s',r}p(s',r\vert s,a)\left[r+\gamma v(s')\right]\\ &=\max_a\mathbb E\left[R_{t+1}+\gamma v(S_{t+1})\vert S_t=a, A_t=a\right]\\ \end{align*}\]로 정의하자($s\in\mathcal S$). 먼저 언급할 것은 $\bar{\mathcal T}$의 정의에 따르면 $v$에 대한 Bellman optimal equation이
\[v_\ast(s)=(\bar{\mathcal T}v_\ast)(s)\quad s\in\mathcal S\]로 쓰여질 수 있다는 사실이다. 또한, Bellman optimal equation이 식의 개수와 변수의 개수가 같은 (비선형) 연립방정식이므로 특수한 상황이 아닌 이상은 해가 하나이고, 따라서 모든 $s\in\mathcal S$에 대하여 $v=(\bar{\mathcal T}v)(s)$를 만족시키는 어떤 $v$가 있다면 그 $v$는 optimal value function이라는 것도 알 수 있다.
증명에 앞서 절댓값과 최댓값에 관한 간단한 다음 식 $(\ast)$을 참고하자.
\[\begin{aligned} \left|\max_af(a)-\max_ag(a)\right| &=\max_af(a)-\max_ag(a)\\ &=f(a_\ast)-\max_ag(a)\\ &\le f(a_\ast)-g(a_\ast)\\ &\le\max_a\left|f(a)-g(a)\right|\\ \end{aligned} \tag{$\ast$}\]이때, 일반성을 잃지 않고 $\max_a f(a)\ge \max_ag(a)$로 두었고 $a_\ast=\text{arg}\max_af(a)$로 두었다.
먼저, $\bar{\mathcal T}$가 contraction mapping이라는 것을 증명한다. 임의의 $v$, $w$에 대하여 식 (4.10)에 의해 정의된 점화식인
\[\begin{align*} \left|(\bar{\mathcal T} v)(s)-(\bar{\mathcal T} w)(s)\right| &=\left| \max_a\sum_{s',r}p(s',r\vert s,a)\left[r+\gamma v(s')\right] -\max_a\sum_{s',r}p(s',r\vert s,a)\left[r+\gamma w(s')\right] \right|\\ &\stackrel{(\ast)}{\le} \max_a\left| \sum_{s',r}p(s',r\vert s,a)\left[r+\gamma v(s')\right] -\sum_{s',r}p(s',r\vert s,a)\left[r+\gamma w(s')\right] \right|\\ &\le\gamma\max_a\sum_{s',r}p(s',r\vert s,a)\left|v(s')-w(s')\right|\\ &=\gamma\sum_{s',r}p(s',r\vert s,a_\ast)\left|v(s')-w(s')\right|\\ &=\gamma\mathbb E\left[ \left|v(S_{t+1})-w(S_{t+1}))\right|\;\vert S_t=s, A_t=a_\ast \right]\\ &\le\gamma\max_{s'}|v(s')-w(s')|\\ &=\gamma\left\Vert v-w\right\Vert_{\infty} \end{align*}\]이다. 첫번째 줄은 기호의 정의, 두번째 줄은 $(\ast)$, 세번째 줄은 삼각방정식을 사용했다. 네번째 줄에서는 세번째 줄의 argmax를 $a_\ast$로 잡은 것이고 다섯번째 줄은 기호의 정의에 의해 당연하다. 여섯번째 줄은 $A_t=a_\ast$인 상황보다도 더 크게 최댓값을 잡을 수 있기 때문이며, 일곱번째 줄은 기호의 정의로부터 당연하다.
이제 좌변에 $\max_s$를 취하면
\[\left\Vert\bar{\mathcal T} v-\bar{\mathcal T} w\right\Vert_\infty \le\gamma\Vert v-w\Vert_\infty\]이다. 따라서 $\bar{\mathcal T}$는 contraction mapping이다. 그러면 contraction principle에 의해, 임의의 $v_0:\mathcal S\to\mathbb R$에 대하여 점화식 (4.10) 혹은
\[v_{k+1}=\bar{\mathcal T}v_k\]에 의해 정의된 수열 $\{v_k\}_{k=0}^\infty$는 수렴한다.
조금 더 정확하게는, 어떤 $K$에 대하여 $v_{K+1}=v_K$가 되는데 그러면 $v_K=\bar{\mathcal T}v_K$이 되어 $v_K$가 $\bar{\mathcal T}$의 fixed point가 된다. 그런데 $\bar{\mathcal T}$의 유일한 고정점은 $v_\ast$이므로 $v_K=v_\ast$이다.
\[\lim_{k\to\infty} v_k=v_\ast\]이다. 여기서 극한은 $\Vert\cdot\Vert_\infty$의 관점에서의 극한이다. 이로써 value iteration의 증명이 완성되었다. $\square$
Sutton 책의 pseudocode는 다음과 같다.

4.4.1 코드 구현
다음과 같이 코드를 짜봤다. 이전 코드는 claude의 도움을 적극적으로 받았는데, 이번에는 내가 직접 초안을 짜봤다. 하지만 display하는 부분에 있어서는 다시 claude의 도움을 받았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
from env import GridWorld
env = GridWorld()
V_init = {s: 0.0 for s in env.get_states()}
def value_iteration(V, theta=0.001):
"""Value Iteration"""
print(f"\n{'='*60}")
print(f"Value Iteration")
print(f"{'='*60}\n")
iteration = 0
while True:
iteration += 1
delta = 0
for state in env.get_states():
if env.is_terminal(state):
continue
v_old = V[state]
action2values = {}
for action in env.actions:
next_state = env.get_next_state(state, action)
reward = env.get_reward(state, action)
action2values[action] = reward + env.gamma * V[next_state]
V[state] = max(action2values.values())
delta = max(delta, abs(v_old - V[state]))
# Iteration별 출력
print(f"[Iteration {iteration}] delta = {delta:.6f}")
print_V(V)
print()
if delta < theta:
break
# Policy 추출
policy = {}
for state in env.get_states():
if env.is_terminal(state):
continue
action2values = {}
for action in env.actions:
next_state = env.get_next_state(state, action)
reward = env.get_reward(state, action)
action2values[action] = reward + env.gamma * V[next_state]
policy[state] = max(action2values, key=action2values.get)
# 최종 결과
print(f"{'='*60}")
print("Final Policy")
print(f"{'='*60}")
print_policy(policy)
return policy, V
def print_V(V):
"""Value Function만 출력"""
for r in range(env.rows - 1, -1, -1):
row = []
for c in range(env.cols):
if (r, c) == env.wall:
row.append(" WALL ")
else:
row.append(f"{V[(r,c)]:6.2f}")
print(" ".join(row))
def print_policy(policy):
"""Policy만 출력"""
for r in range(env.rows - 1, -1, -1):
row = []
for c in range(env.cols):
if (r, c) == env.wall:
row.append(" W ")
elif env.is_terminal((r, c)):
row.append(" T ")
else:
row.append(f" {policy[(r,c)]} ")
print(" ".join(row))
# 실행
policy, V = value_iteration(V_init.copy())
4.4.2 구현 결과
결과를 보니 6번의 iteration 끝에 optimal policy에 도달한 것이 보인다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
============================================================
Value Iteration
============================================================
[Iteration 1] delta = 1.000000
-0.10 -0.10 1.00 0.00
-0.10 WALL -0.10 0.00
-0.10 -0.10 -0.10 -0.10
[Iteration 2] delta = 0.900000
-0.19 0.80 1.00 0.00
-0.19 WALL 0.80 0.00
-0.19 -0.19 -0.19 -0.19
[Iteration 3] delta = 0.810000
0.62 0.80 1.00 0.00
-0.27 WALL 0.80 0.00
-0.27 -0.27 0.62 0.46
[Iteration 4] delta = 0.729000
0.62 0.80 1.00 0.00
0.46 WALL 0.80 0.00
-0.34 0.46 0.62 0.46
[Iteration 5] delta = 0.656100
0.62 0.80 1.00 0.00
0.46 WALL 0.80 0.00
0.31 0.46 0.62 0.46
[Iteration 6] delta = 0.000000
0.62 0.80 1.00 0.00
0.46 WALL 0.80 0.00
0.31 0.46 0.62 0.46
============================================================
Final Policy
============================================================
R R R T
U W U T
U R U L
4.6 Generalized Policy Iteration
4.5절은 그다지 많이 언급할 내용이 없고, 굳이 따지자면 이전 포스트에서 이미 asyncronous policy evaluation에 대해 말했으므로 넘어가도 되겠다. 하지만 4.6절의 GPI는 중요하므로 쓰고 넘어가려 한다.
policy iteration(정책반복)은 policy evaluation(정책평가)와 policy improvement(정책개선)을 반복적으로 적용해 optimal policy $\pi_\ast$와 optimal value function $v_\ast$에 수렴해나가는 것을 말한다고 했다. 여기서 Sutton은 강화학습의 대부분의 알고리즘이 이러한 두 과정의 반복으로 되어있음을 말하고 있다. 이 장에서 설명된 것만 해도 PE에서 state를 업데이트하는 방식에 따라 syncronous / asyncronous 버전의 두 가지 방식이 있고, sweep의 빈도에 따라 one-sweep / $k$-sweep / full sweep의 여러 방식으로 나뉠 수 있어서 policy iteration도 여러 방식이 있다고 말할 수 있지만 모두 PE와 PI를 반복해나간다는 점에서는 동일한 것이다. 이러한 일반적인 policy iteration 방식을 GPI라고 부른다.
아래 두 그림은 generalized policy iteration을 아주 잘 설명하는 Sutton 책의 그림이다.
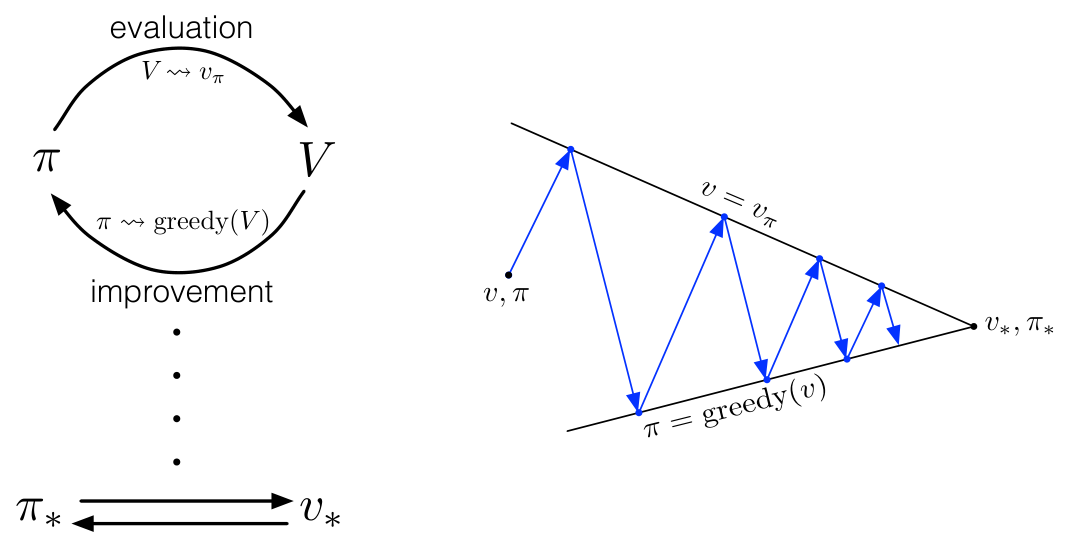
두 과정이 서로를 보완하며 답을 찾아나간다는 점에서 GAN(generative adversarial network)을 떠올리게 한다. 또한, 현대 강화학습 주류인 actor-critic 방식도 GPI의 관점에서 해석될 수 있다. critic은 정책 평가를 수행하는 도구이며, critic update를 한 번 하고 나면 정책을 개선하게 되는데 그 개선하는 대상이 actor이기 때문이다.
GAN과 actor-critic은 수렴조건을 찾기가 어려운 것으로 알려져 있다. 하지만 DP는, 꽤 간단한 세팅에서 수렴 조건이 보장된다는 것이 수학적으로 증명된 알고리즘이다. 그런 점에서 정말로 강화학습 모든 알고리즘들의 기본이라고 할 만하다.
지금까지 세 포스트를 통해 각각
- policy evaluation
- policy improvement와 policy iteration
- value iteration과 GPI
를 다뤄봤다. 세 포스트에는 모두 증명이 포함되어 있는데 그중 두번째 포스트의 증명은 좀 간단한 증명이었다. 그래도, DP의 주요한 알고리즘들인 policy iteration과 value itertation에 대하여 완전한 증명을 해내어 뿌듯하다. 다만 모든 종류의 policy evaluation에 대하여 증명한 것은 아니고 syncronous full-sweep PE에 대해서만 증명했다.
이번 기회에 (관련 회사 자료를 만들면서) Sutton의 책을 13장까지 주요 내용들만 쭉 읽게 되었는데 어느 정도 이해가 되면서 읽고 있어서 뿌듯하다. 하지만, 4장의 다음 장에 나오는 Monte Carlo와 Temporal Difference에 대해서는 증명을 할 수 있을 지 모르겠어서 더 포스트를 쓸 지는 모르겠다.
댓글남기기